Batch Deployments
Preface
Given a successful build, you can deploy your model as a batch application.
This deployment type allows you to run batch inference executions in the system, and handle data files from an online cloud storage provider.
Deployment Configuration
| Paramater | Description | Default Value |
|---|---|---|
| Model ID [Required] | The Model ID, as displayed on the model header. | |
| Build ID [Required] | The Qwak-assigned build ID. | |
| Initial number of pods | The number of k8s pods to be used by the deployment. Each pod handles one or more files/tasks. | 1 |
| CPU fraction | The CPU fraction allocated to each pod. The CPU resource is measured in CPU units. One CPU, in Qwak, is equivalent to: 1 AWS vCPU 1 GCP Core 1 Azure vCore 1 Hyperthread on a bare-metal Intel processor with Hyperthreading | 2 |
| Memory | The RAM memory (in MB) to allocate to each pod. | 512 |
| IAM role ARN | The user-provided AWS custom IAM role. | None |
| GPU Type | The GPU Type to use in the model deployment. Supported options are, NVIDIA K80, NVIDIA Tesla V100, NVIDIA T4 and NVIDIA A10. | None |
| GPU Amount | The number of GPUs available for the model deployment. Varies based on the selected GPU type. | Based on GPU Type |
| Purchase Option | Choose between on-demandor spot instances for the batch executions. | None (spot) |
| Service Account Key Secret Name | The service account key secret name to reach Google cloud services | None |
Batch Deployment from the UI
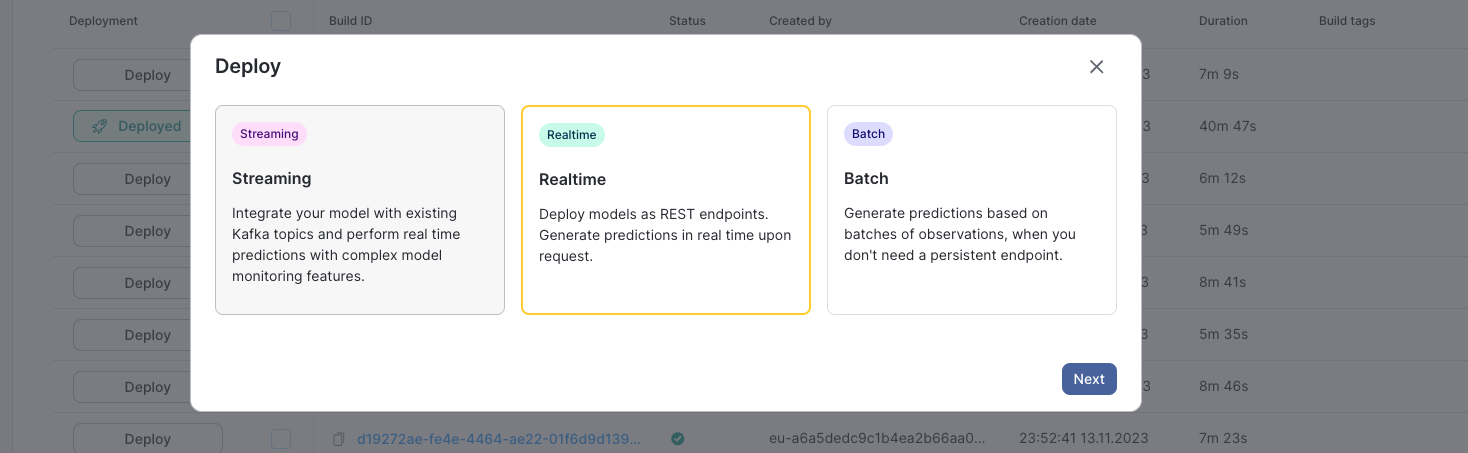
To deploy a batch model from the UI:
- In the left navigation bar in the Qwak UI, select Models and select a model to deploy.
- Select the Builds tab. Find a build to deploy and click the deployment toggle. The Deploy dialog box appears.
- Select Batch and then select Next.
Batch Deployment from the CLI
To deploy a model in batch mode from the CLI, populate the following command template:
qwak models deploy batch \
--model-id <model-id> \
--build-id <build-id> \
--pods <pods-count> \
--cpus <cpus-fraction> \
--memory <memory-size>
For example, for the model built in the Getting Started with Qwak section, the deployment command is:
qwak models deploy batch \
--model-id churn_model \
--build-id 7121b796-5027-11ec-b97c-367dda8b746f \
--pods 4 \
--cpus 3 \
--memory 1024
Updated 4 months ago
What’s Next
Next, let's look at the different options for performing batch predictions