Managing Data
Learn how to upsert, search and delete vectors in the vector store.
Before inserting data into the vector store, a collection must be created. To create a collection, please follow the guidelines on the Collections page.
Once you've created your first collection, you can easily start managing your data.
Creating a collection
For this tutorial, we'll use an example collection named
product_catalog:from qwak.vector_store import VectorStoreClient client = VectorStoreClient() catalog_collection = client.create_collection(name="product_catalog", description="A product catalog", dimension=3, metric="cosine")
Upserting vectors
Upserting vectors allows you to either add new or replace existing vectors.
- Each vector must have a unique UUID4 formatted ID.
- The vector size must match the dimension of the collection.
Non-multitenant collections
from qwak.vector_store import VectorStoreClient
client = VectorStoreClient()
collection = client.get_collection_by_name("product_catalog")
collection.upsert(
ids=[
"70165628-d42c-48b7-bba1-f86006b201c0"
],
vectors=[
[0.1, 0.2, 0.3]
],
properties=[{
"name": "shoes",
"color": "black",
"size": 42.5,
"price": 19.99
}]
)
Multitenant collections
When upserting against a multitenant collection, a tenant ID must be specified for each vector. a valid tenant ID is a string that matches "[a-zA-Z0-9_-]{4,64}$
from qwak.vector_store import VectorStoreClient
client = VectorStoreClient()
collection = client.get_collection_by_name("product_catalog")
collection.upsert(
ids=[
"70165628-d42c-48b7-bba1-f86006b201c0"
],
tenant_ids = ["tenant1"],
vectors=[
[0.1, 0.2, 0.3]
],
properties=[{
"name": "shoes",
"color": "black",
"size": 42.5,
"price": 19.99
}]
)
Batch sizes and parallel upsert
Qwak SDK groups the vectors into batches before sending them to backend Vector Store. by default, the batch size is 1000, but can be configured using the
batch_sizeargument ofCollection.upsert<>You can also configure parallel insertion, where multiple concurrent requests are made to both the vectorizer and the backend Vector Store - this is useful in cases where a large dataset needs to be inserted.
You can enable/disable parallel insertion using the
multiprocargument (defaults toFalse); when parallel insert is enabled, you can also control the max number of processes usingmax_processes, which defaults to the number of CPUs on your machine.
Upserting vectors via CSV files
A simple way to ingest bulk data is by uploading data as CSV files from the Qwak UI.
The uploaded files mush contain an id, and either an input or a vector columns.
CSV columns:
id- UUID representing the rowinput(optional) - Textual values that will be converted to embedding vectors via the Vectorizer modelvector(optional) - Vector values that will be directly ingested into the Vector Store
Upserting natural input data
Adding natural input data allows you to automatically use the vectorizer model to convert data into an embedding vector in a simple command.
- Each data input must have a unique UUID4 formatted ID.
- The vectorizer output size must match the dimension of the collection.
from qwak.vector_store import VectorStoreClient
client = VectorStoreClient()
collection = client.get_collection_by_name("product_catalog")
collection.upsert(
ids=[
"70165628-d42c-48b7-bba1-f86006b201c0"
],
natural_inputs=[
"black sports shoes"
],
properties=[{
"name": "shoes",
"color": "black",
"size": 42,
"price": 19.99
}]
)
The same as with vector upsert, parallel insertion is supported in this case as well.
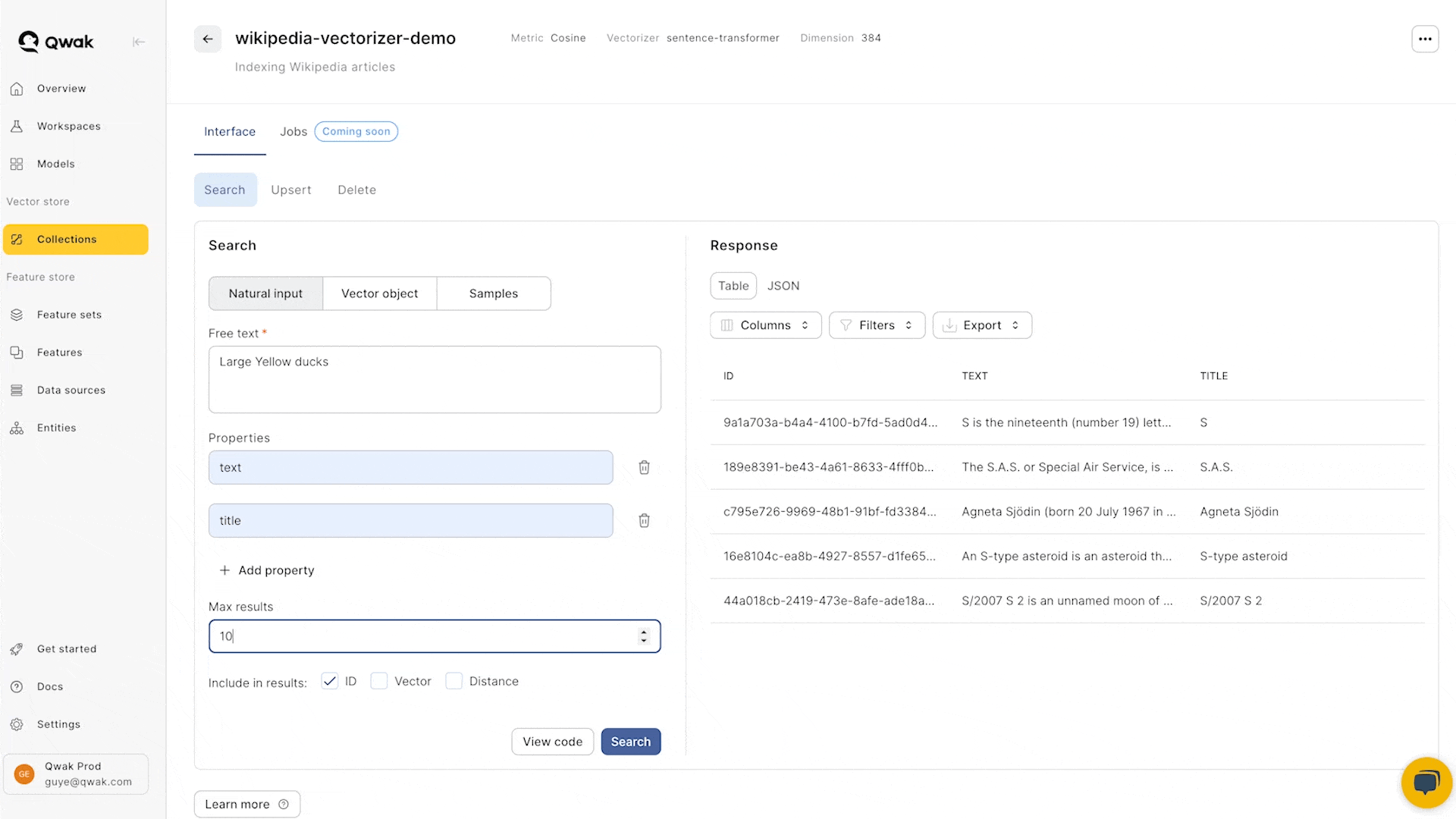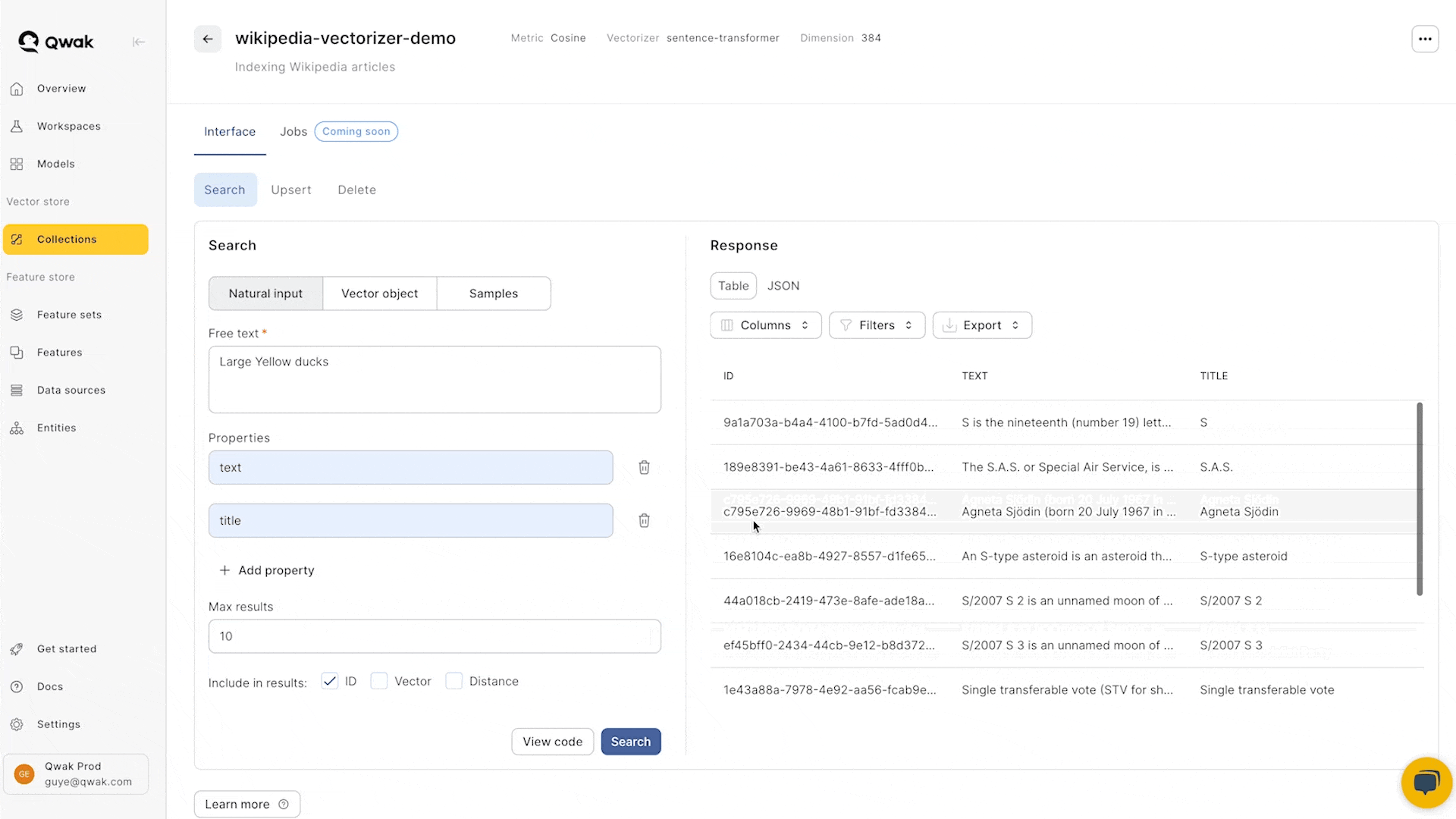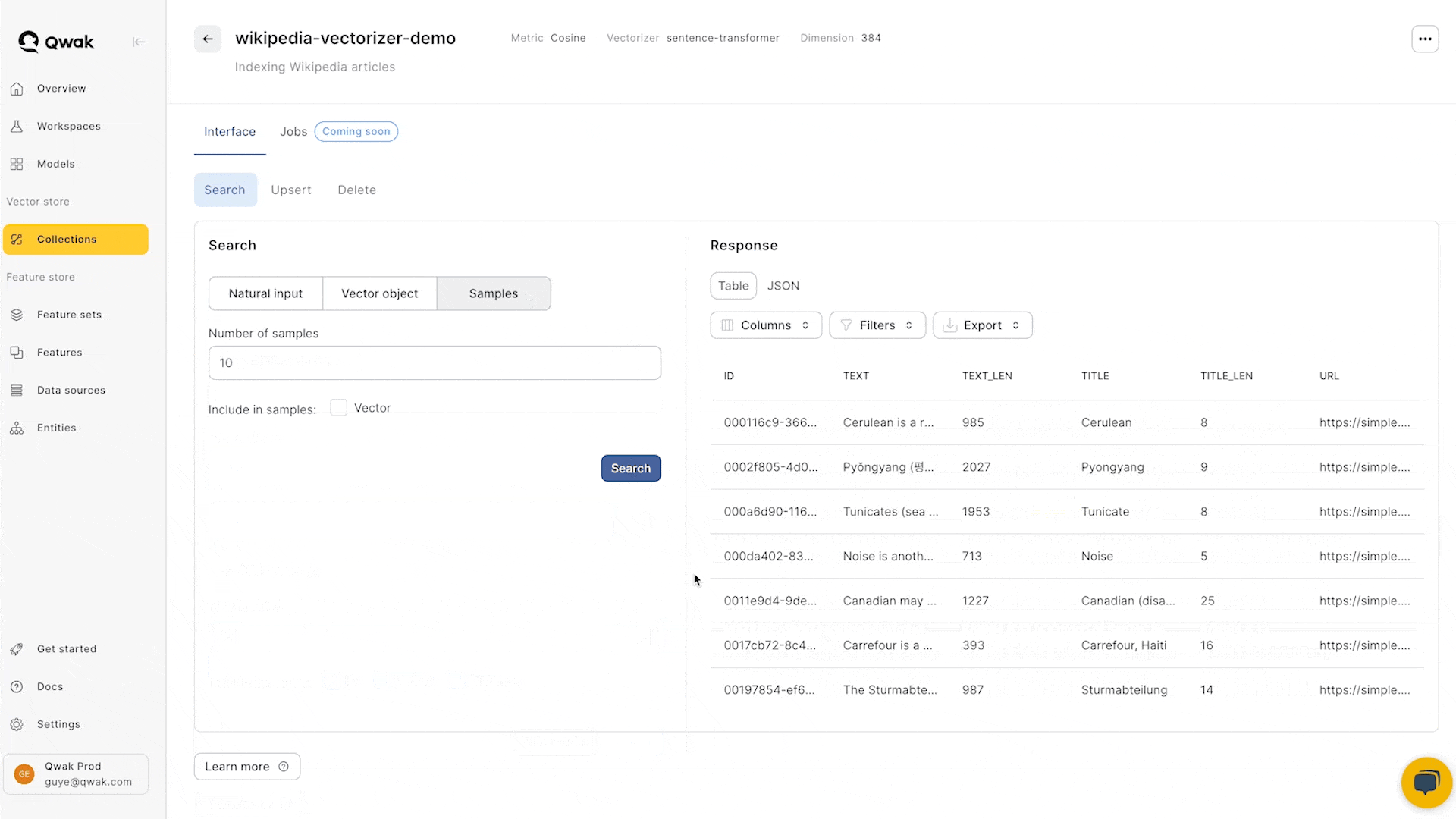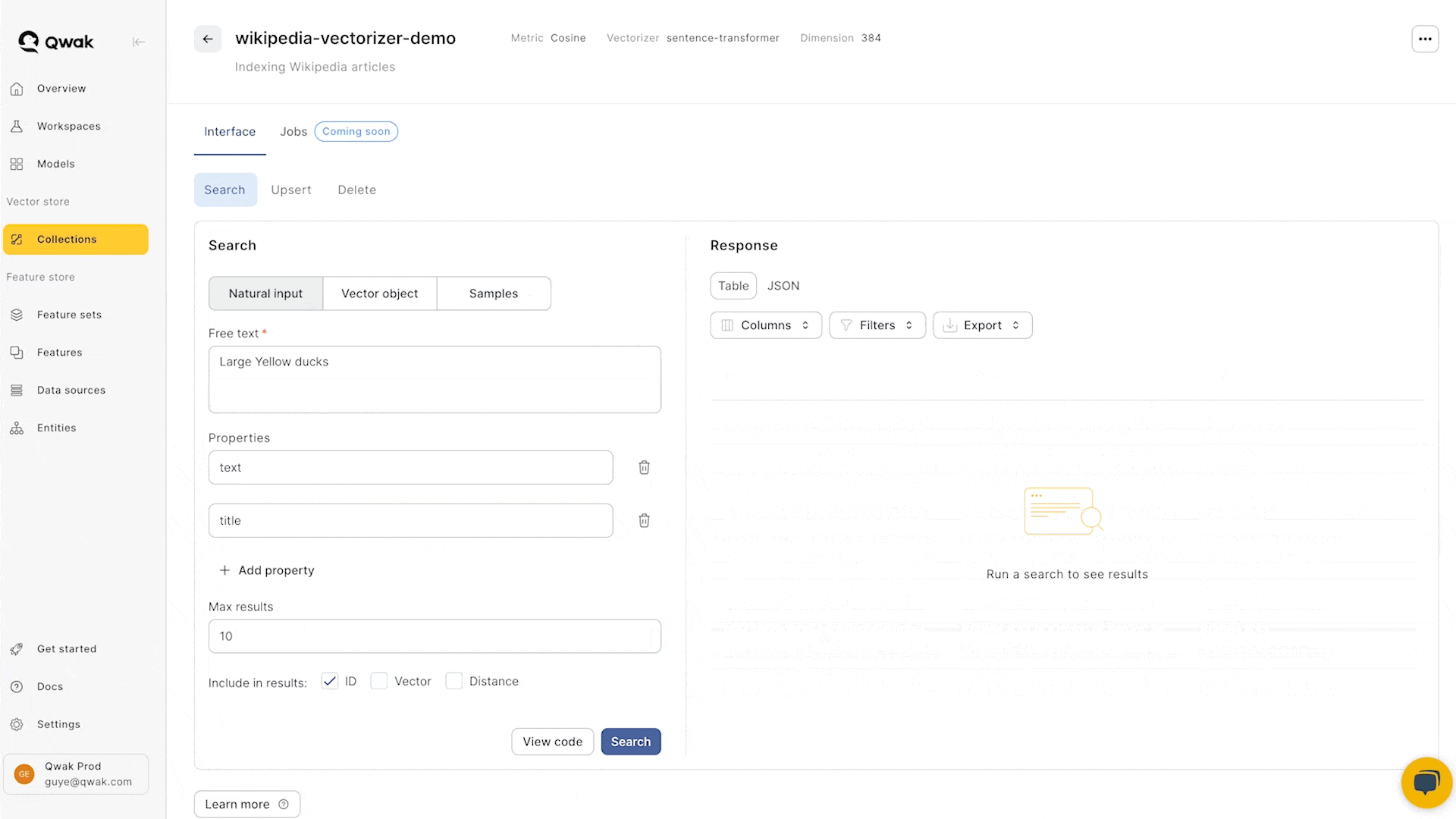
Searching vectors
Searching using a reference vector allows you to find similar vectors based on a given input vector.
- The vector size must match the dimension of the collection
- Choose properties to include in the vector response.
- The similarity distance and matched vectors may be optionally returned in the response
from qwak.vector_store import VectorStoreClient
client = VectorStoreClient()
collection = client.get_collection_by_name("product_catalog")
search_results = collection.search(output_properties=["name", "color", "size", "price"],
vector=[0.1, 0.2, 0.3],
top_results=5,
include_id=True,
include_vector=False,
include_distance=False,
tenant_id=<TENANT_ID> # Multi-Tenant collections ONLY!
)
Searching vectors by natural input
Search using natural input allows you to find similar vectors based on a given text.
- A vectorizer model must be defined for this collection.
- The vectorizer embedding dimension must match the dimension of the collection
- Choose properties to include in the response.
- The similarity distance and matched vectors may be optionally returned in the response
from qwak.vector_store import VectorStoreClient
client = VectorStoreClient()
collection = client.get_collection_by_name("product_catalog")
search_results = collection.search(output_properties=["name", "color", "size", "price"],
natural_input="Black shoes",
top_results=5,
include_id=True,
include_vector=False,
include_distance=False,
tenant_id=<TENANT_ID> # Multi-Tenant Collections ONLY!
)
Filtering vectors
Searching vectors using filters allows you to find vector similarity based on a given reference vector.
- The vector size must match the dimension of the collection
- Choose properties to include in the vector response.
- The similarity distance and matched vectors may be optionally returned in the response
Pre-filtering Vectors
Qwak supports vector pre-filtering for faster and more efficient search queries. When creating a filtered search, Qwak first filters the data by the metadata, and only later does the vector search.
This helps in faster and more efficient search operations, especially in larger vector datasets.
from qwak.vector_store import VectorStoreClient
client = VectorStoreClient()
collection = client.get_collection_by_name("product_catalog")
# Search filtered properties
filtered_search_results = collection.search(
output_properties=["name", "color", "size", "price"],
natural_input="Black sport shoes",
filter=GreaterThan(property="size", value=10.99)
)
print(filtered_search_results)
Search Filters
The following filters are available when search for vectors, and may be concatenated to create more elaborate filters.
from qwak.vector_store.filters import And, Or, Equal, Filter, \ GreaterThan, GreaterThanEqual, IsNotNull, IsNull, LessThan, \ LessThanEqual, Like, NotEqual # Filtering example filtered_search_results = collection.search( output_properties=["name", "color", "size", "price"], natural_input="Black sport shoes", filter=Or( GreaterThan(property="size", value=10.99), Equal(property="name", value="shoes") ) )
Deleting vectors
Deleting a vector is made by supplying the UUID of the saved vector.
from qwak.vector_store import VectorStoreClient
client = VectorStoreClient()
collection = client.get_collection_by_name("product_catalog")
collection.delete(
vector_ids=["70165628-d42c-48b7-bba1-f86006b201c0"]
tenant_ids=[<TENANT_ID>] # Multi-Tenant Collections ONLY!
)
Updated 4 months ago